CUDA基础与自动求导教学文档
1 前言
相比于一般的CPU代码,CUDA代码可以充分利用GPU中更多的运算核心。适合用于大规模的并行计算,提高运算效率。然而,CUDA代码的门槛比较高,代码比较复杂,并且不易debug。只有充分了解原理,才能减少失误,提高编程效率。
网上有许多很详细的CUDA编程教学。如果我哪里描述得不清楚,可以自行去网上搜搜看。如果有什么意见建议,也欢迎大家指出,我会尽快更新。
2 CUDA基础知识
2.1 文件格式
“.cu” 文件中可以含有在GPU上调用/执行的代码,所以一般会用 “.cu” 代替 “.cpp”。而头文件依然可以沿用 “.h”,当然,使用 “.cuh” 作为在CPU上的函数的头文件在结构上更为合理。
2.2 前缀
在CUDA中,host 和 device 是两个重要的概念,我们用 host 指代CPU及其内存,而用 device 指代GPU及其内存。因此,为了区分变量的位置,变量名一般会有前缀:host_,device_,也可以省略为 h_,d_。
- 函数一般分为三种:
- 在CPU上调用,在CPU上执行;
- 在CPU上调用,在GPU上执行;
- 在GPU上调用,在GPU上执行。
分别对应以下三种关键字:__host__,__global__,__device__。使用时声明在函数前面即可,甚至可以声明两种,比如:
1 | __host__ __device__ void func_1(float& A); |
这样函数 func_1 既可以在CPU上调用执行,也可以在GPU上调用执行。
__host__ 函数就是c++中最普通的函数,所以一般可以省略不写,只有在同时声明 __host__ 和 __device__ 的时候才有必要强调。
__global__ 函数必须为 void 类型,因为涉及到CPU与GPU之间的信息传输。调用的时候是在CPU上,比如说在
"main.cu"里,但是函数内部是在GPU上的。- __device__ 函数一般调用的时候是在 __global__ 函数内部。
2.3 流程
一般的代码流程为:
- 分配CPU、GPU上的内存空间。
- 将变量、参数等从CPU拷贝到GPU分配好的空间上。
- 使用 __global__ 函数从CPU端调用GPU的空间进行并行运算。
- 将计算结果从GPU拷贝到CPU上并保存。
- 释放CPU、GPU的内存。
这5步可以与C++中的类(class)结合,1、2步放在构造函数中,3、4步放在普通函数中,5步放在析构函数中。
2.4 内存相关
2.4.1内存分配
对于CPU数组直接 malloc 就好。
1 | h_vertices = (float *)malloc(N * sizeof(float)); |
或者使用锁页内存。好像说在拷贝时速度更快?具体请查询 nvidia文档。
1 | cudaHostAlloc(&h_vertices_2, N * sizeof(float), cudaHostAllocDefault); |
对GPU数组可以使用 cudaMalloc 函数。
1 | cudaMalloc(&d_vertices, N * sizeof(float)); |
分配空间一般可以放在类的构造函数里,避免后续使用时因为忘记分配空间而报错。
注:在分配前一定要先声明该变量。声明一般放在类的头文件中。如:
1 | private: |
2.4.2 内存释放
使用完毕后,针对上面的三种申请方式,分别使用以下释放方式就好。
1 | free(h_vertices); |
1 | cudaFreeHost(h_vertices_2); |
1 | cudaFree(d_vertices); |
内存释放可以放在类的析构函数中。
2.4.3 内存拷贝
分为四种类型:CPU到CPU,CPU到GPU,GPU到CPU,GPU到GPU。
分别对应四个指令:udaMemcpyHostToHost,cudaMemcpyHostToDevice,cudaMemcpyDeviceToHost,cudaMemcpyDeviceToDevice。
使用 cudaMemcpy 函数来拷贝,以第二种为例:
1 | cudaMemcpy(d_vertices, h_vertices, N * sizeof(float), cudaMemcpyHostToDevice); |
其中d_vertices、h_vertices都是已经分配好空间的,长度为N的float类型数组。d_、h_分别代表该数组位于GPU和CPU上(前文有提到)。
cudaMemcpy函数只能在CPU中调用。cudaMemcpy中四个参数依次是:拷贝目的地的起始地址、需要拷贝的数组的起始地址、拷贝长度(以字节为单位)、拷贝类型。cudaMemcpy在拷贝前会执行同步函数cudaDeviceSynchronize();,所以如果想并行执行拷贝命令,可以使用异步拷贝:cudaMemcpyAsync,并加入第五个参数:cuda流。这在后面会提到。例:1
cudaMemcpyAsync(d_vertices, h_vertices, N * sizeof(float), cudaMemcpyHostToDevice, stream[0]);
注:前两个参数都是起始地址,所以对于CPU上 float 类型的常量,在输入 cudaMemcpy 函数时要使用 &取地址。但 GPU 常量一般无法在 __host__ 函数中声明,所以要声明数组,再分配空间。例:
1 | float h_eta = 1.49; |
2.5 核函数
从流程中可以看到,__global__ 函数是 cuda 并行计算的核心,所以我们一般也称之为核函数(kernel\ function)。
核函数在调用时需要声明 $<<
1 | func_2 <<<blkPGrd, thrPBlk>>> (input, output, N); |
其中 func_2 是一个 __global__ 函数,blkPGrd 和 thrPBlk 都是 dim3 类型的变量,dim3 可以理解为无符号整型的三维向量 (x,y,z)。
在定义 blkPGrd 和 thrPBlk 时,系统会默认缺失值为1。这样会方便我们使用一维、二维向量。比如:
1 | dim3 blkPGrd(3,2); |
x 的值就是 0,1,2 中的一个,y 的值就是 0,1 中的一个。
一般来说一维就够用了,计算起来更方便,并且可以直接用 int 类型初始化 blkPGrd 和 thrPBlk。
注:这里的 input、output 等参数,包括 N 要么用指针(*),要么传地址(\&)。尽量不要直接(int N)传值,尤其是非标量的参数,因为传值会先把这个值复制到GPU上,再进行计算。影响效率不说,更增加了出错几率。所以,这些参数都要提前在GPU上分配好空间,因为核函数内部使用的参数是在GPU上的。
当执行到核函数内部,我们认为此时已经在GPU上了。首先需要计算出线程的序号,并忽略超出的部分。例如:
1 | __global__ void func_2 (float* input, float* output, const int& N) |
关于 2、3维的使用请参考网上的教程吧。处理矩阵、图片相关的问题会稍微方便一些。不过用一维 index/ 每行的个数 n 就可以得到行idx,用 index\%n 就可以得到列 idx,和二维 index 的 idx.x、idx.y 本质上是一样的。
2.6 结构
讲了这么多还不清楚blkPGrd和thrPBlk到底有什么意义啊?为什么要起这两个名字啊?这就要从GPU的结构说起了。
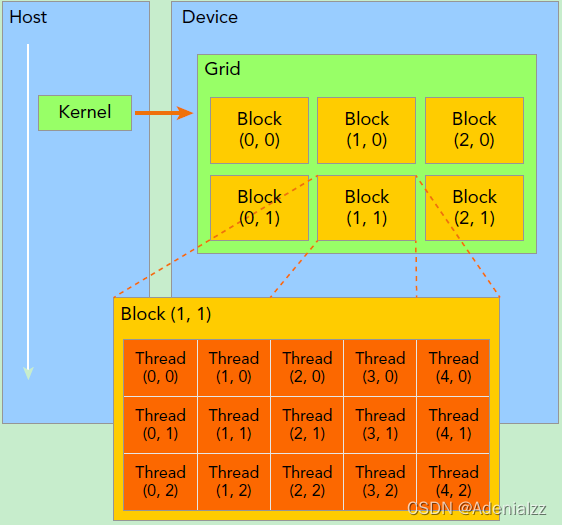
|
图片为 CUDA结构示意图,其中 blkPGrd(3,2), thrPBlk(5,3);
图片节选自:https://blog.csdn.net/weixin_44966641/article/details/124448102
GPU的最小单元是线程(thread),一般的显卡中32个线程为一束(warp)。运行时,如果命令一致,这一束线程会同时执行命令(并行);而如果命令不一致,这32个线程就会依次执行每种命令(串行)。这是GPU的物理结构导致的。所以如果核函数中的if分支很多,导致每一束的线程经常分在不同的if分支中,就会影响并行效率。不过准确性是一定可以保证的,如果不追求极致效率,if分支多一些也无妨。
多个线程构成一个线程块(block)。thrPBlk是 threadsPerBlock 的缩写(我自己瞎缩的),即每个线程块中的线程个数。通常为32(一线程束)的倍数。每种显卡的上限不同,3090最多好像是1024,有些老显卡只支持256。不过thrPBlk也不是越大越好。运算速度具体和什么有关俺也不太清楚。为了在不同服务器上能正常运行,我一般写成256,经过测试速度和512基本一样。
而多个线程块构成一个网格(grid)。blkPGrd是blocksPerGrid的缩写,即每个网格中的线程块个数。这一数目往往是根据你需要的线程总数决定的。比如你优化的网格有N个三角形,每个线程控制一个三角形,即总共需要至少N个线程,那么在一维情况下就是:
1
blkPGrd = (N + thrPBlk - 1) / thrPBlk;
公式可以留作思考题,如果你理解了GPU结构,这个公式是很容易推出来的。
==思考题2:==为什么不写成如下形式?想不出来可以来问我:)
1
blkPGrd = (N - 1) / thrPBlk + 1;
最后做个形象的类比:某小学校长需要拧 1200 个螺丝。学校每个年级 256 个学生,平均分为 8 个班,每班 32 人。则需要 (1200 + 256 - 1) / 256 = 5 个年级就够了,总共调用了 5 * 256 = 1280 个学生。这样就多出 80 个幸运儿可以摸鱼,也就是上面代码中超过 N 的部分直接 return。而 blkPGrd 如果取 4 及以下就拧不完螺丝,如果取 6 及以上就有更多的学生没螺丝拧。
2.7 CUDA流
某些时候,多个核函数是可以并行的。比如我们想对于input_a和input_b分别依次执行func_2和func_3,但a、b之间是独立的。直接写代码就会变成以下这样:
1 | func_2 <<<blkPGrd, thrPBlk>>> (input_a, output_a, N); |
但上面四条语句是依次执行的,效率不够高。此时就可以用到 cuda流。同一个流内是依次执行的,但不同流之间不会互相影响。这样就可以完美解决上面的问题。使用方法为:
声明cuda流变量:以下二者均可,之后以第一种为例。
1
2
3cudaStream_t stream[2];
cudaStream_t stream0, stream1;创建流:
1
cudaStreamCreate(&stream[k]);(k=0,1)
修改上面四句话为:
1
2
3
4
5
6
7
8
9func_2 <<<blkPGrd, thrPBlk, 0, stream[0]>>> (input_a, output_a, N);
func_2 <<<blkPGrd, thrPBlk, 0, stream[1]>>> (input_b, output_b, N);
func_3 <<<blkPGrd, thrPBlk, 0, stream[0]>>> (input_a, output_a, N);
func_3 <<<blkPGrd, thrPBlk, 0, stream[1]>>> (input_b, output_b, N);
cudaDeviceSynchronize();这一行为同步函数,作用是等待两个流全部执行完将运算同步方便后续运算。
在运行的时候,先开始执行第一行的核函数 func_2。紧接着就会读取第二行。由于第二行用的流 stream[1] 是空闲的,会同时执行第二行的核函数 func_2。紧接着读取第三行。直到第一行运行完毕,stream[0] 变成空闲的,第三行核函数 func_3 才会被执行。同理,直到第二行运行完毕,stream[1] 变成空闲的,第四行核函数 func_3 才会被执行。
销毁cuda流:
1
cudaStreamDestroy(stream[k]);(k=0,1)
注1:尖括号中第三个变量的含义是共享内存,一般用不到,写 0 就完事了。如果需要的话再参考网上教程吧。
注2:当尖括号中只有 blkPGrd,thrPBlk 这两个变量时,调用默认cuda流。读取第二行时,由于默认流被占用,所以会等到第一行运行完默认流变成空闲的时候才会执行第二行。尖括号中要么写两个变量要么写四个,不能只写三个。
注3:流的上限好像是1024?但是一般用不到那么多流,十几个就顶天了。并不是流越多执行就越快,如果GPU核心不够了,就算流是空闲的也不会执行该语句。
2.8 CUDA运算库的使用
除了自己编写核函数之外,也可以用许多现成来调用GPU做计算。例如线性代数库cuBLAS,稀疏矩阵库cuSPARSE,规约计算库Thrust等等。具体的请参考Cuda Toolkit官方文档 这里着重介绍一下cuBLAS吧,毕竟对我们来说用得最多。
声明cublashandle变量:
1
cublasHandle_t handle[2];
创建handle:
1
cublasCreate(&handle[k]);(k=0,1)
将 handle 与 cuda流绑定(在 cudaStreamCreate 之后):
1
cublasSetStream(handle[k], stream[k]);(k=0,1)
设置指针类型:
1
cublasSetPointerMode(handle[k], CUBLAS_POINTER_MODE_DEVICE);(k=0,1)
默认类型为
CUBLAS_POINTER_MODE_HOST。用 host 上的变量来储存计算结果,包含了 “在GPU上计算结果” 和 “将结果拷贝回CPU” 两步。即相当于CUBLAS_POINTER_MODE_DEVICE + cudaMemcpyDeviceToHost。由于拷贝之前会先同步,等待前面的代码全部执行完毕,所以不适用于多流并行。当然如果只使用一次的话可以去掉这一步使用默认指针类型。
以平方和运算为例,其他运算请参照官网文档。
1
2
3
4
5
6
7
8
9cublasSdot(handle[0], 100, output_a, 1, output_a, 1, d_a);
cublasSdot(handle[1], 100, output_b, 1, output_b, 1, d_b);
// 紧接着使用异步拷贝
cudaMemcpyAsync(h_a, d_a, sizeof(float), cudaMemcpyDeviceToHost, stream[0]);
cudaMemcpyAsync(h_b, d_b, sizeof(float), cudaMemcpyDeviceToHost, stream[1]);
// 多流并行计算结束,使用同步函数同步结果。
cudaDeviceSynchronize();
//输出计算结果
printf("h_a = %f, h_b = %f \n", h_a, h_b);销毁handle:
1
cublasDestroy(handle[k]);(k=0,1)